
Performance (i.e. speed) of disk drives has not improved nearly as rapidly as the performance of memory or CPUs, but disk drives have become very inexpensive. This has lead to the use of multiple disk drives to improve performance. With multiple disk drives, separate operations can be done in parallel as long as the operations are on separate disks. Even a single operation can be speeded up if the data to be retrieved or written can be distributed properly across several disks.
The computer industry has agreed on a standard for transparently distributing a file system across multiple disks. It is known by its acronym RAID which stands for Redundant Array of Independent Disks. There are seven different RAID architectures. They all share some common characteristics.
Here are the seven levels:
RAID Level 0
Level 0 is not technically a RAID scheme because it does not include redundancy to improve performance. Data are striped, that is, divided up into strips which are distributed in an orderly fashion across all of the disks. Strips can be blocks or sectors or some other unit. Consecutive strips are mapped to consecutive disks. If there are four disks, strip 1 of a file would be on disk 0, strip 2 of the file would be on disk 1, strip 3 of the file would be on disk 2, strip 4 of the file would be on disk 3, strip 5 of the file would be on disk 0, and so on.
A set of logically consecutive strips that maps exactly one member to each disk is referred to as a stripe. Thus, logical strips 1, 2, 3, and 4 of the file constitute a stripe. This is important, because when the file is read (or written), note that strips 1, 2, 3, and 4 can be read in parallel. This can dramatically improve reads and writes of large files to and from disk.
This performance improvement can only happen if the entire data pathway is completely parallel; that is, not only do the reads happen in parallel, but each disk has to have its own data line to the controller and from the controller to the system bus and eventually to memory.
Note also that this improvement in performance can only happen if the system makes large data requests. However, as we saw, modern I/O systems generally do make large requests, larger than the initial read. If the initial read is for a few bytes, all of which reside on strip 1, most systems now would read the entire file into memory buffers on the assumption that the process is likely to read other strips shortly.
Even without striping, a system with data distributed across multiple disks can show improved performance. Consider a transaction processing system in which there are a large number of requests for small records in a database. If the records are distributed randomly across the disks, several different records can be read at the same time, thus enhancing performance.
RAID level 1
All of the levels of RAID other than 0 incorporate redundancy to preserve data in the event of the loss of data on a disk. One of the most common types of hardware failure in a computer is the head crash of a disk. The read/write head moves very close to the platter, and the platter is spinning very rapidly (typically 3,600 or 7,200 rpm). This requires very fine tolerances. If the head is jarred ever so slightly or if a piece of dust gets between the head and the platter, the platter can get scratched, causing some or all of the data to be lost.
All of the levels of RAID other than 0 incorporate redundancy to preserve data in the event of the loss of data on a disk. Level 1 is the simplest, but is not used much. In level 1, data striping is used as in RAID 0, but each logical disk is mapped to two different physical disks so that every disk has a mirror disk with the same data. With our example, there would be eight disks in the array, and strip 1 would be on both disk 0 and disk 4.
This has two advantages. First, a read request can be made from either of the two disks, whichever involves the minimum seek time plus rotational latency. Second, if a disk crashes and all of its data is lost, recovery is trivial because all of the data is on the mirror disk.
Write operations have to be done twice, but this does not usually impose much of a performance penalty because the two writes can be done in parallel. However, the write time is the time of the slower of the two operations.
The principle disadvantage of RAID level 1 is the cost, since it requires twice as much disk space as the logical disk space.
RAID level 1 is often called mirroring for obvious reasons.
RAID level 3
I will discuss RAID level 3 before RAID level 2 because it is simpler to understand and more widely used.
Both RAID level 2 and level 3 use a parallel access technique in which all member disks participate in every I/O operation. Typically the spindles and the read/write heads are synchronized so that all of the heads are at the same place on each platter at all times. Strips consist of very small units, on the order of a single byte or word. Parity information is also stored to provide error detection and/or error correction. If there is a single bit error, the RAID controller can detect and correct the error immediately without other components of the system being aware of the error.
RAID level 3 has a single parity disk. In the event of a disk failure, the data can be reconstructed. Note that every read and write involves all of the data disks and the parity disk, and that the disks are so synchronized that we can have corresponding bits (or bytes or words) on all of the disks. Typically strips are very small, on the order of a single byte. Thus successive bytes of a file are stored on successive disks.
The parity value is calculated by performing an exclusive or operation on the data bits. One way to think about this is that the value on the parity disk is set to either zero or one in order to make the total number of one bits be an even number.
Here is an example. Suppose that a system has four disks for data and a fifth disk for parity. Strips are one byte wide. The table below shows the bits for four, 8-bit bytes and the value of the parity disk. The columns represent different disks, so there are five columns.
0 1 0 1 0 1 1 1 1 0 0 1 1 1 1 0 0 0 0 0 1 0 0 0 1 0 0 1 1 0 0 1 0 0 1 1 0 0 1 0Thus, the first disk has the byte 01001001, the second disk has the byte 11100010, the third disk has the byte 01100100, and the fourth disk has the value 11100101. These would typically be four consecutive bytes of a file. Note that the value on the parity disk is the result of performing an exclusive or operation on the four bit values.
The parity disk allows for data to be reconstructed in the event of a disk failure. Suppose that the leftmost disk crashes and is completely unreadable. Because of the parity bits, we can reconstruct all of the data on this disk. If you look at the top row, we still have the three data bits 1, 0 and 1, and we know that the parity bit is zero, so we know that the missing value must be zero.
Notice that reads and writes can still be done in parallel. Because there are four disks, four bytes can be read at the same time, thus speeding up the time of reads by a factor of four. In fact, the parity disk is read as well, but is also done in parallel, so there is no time penalty.
There is one parity disk no matter how many data disks there are. If there are 16 data disks, meaning that 16 bytes can be read simultaneously, there is still a single parity disk and if any single disk fails, all of the data can be reconstructed.
RAID level 2
RAID 2 uses Hamming Code. This is a method of storing data redundantly so that errors can be not only detected, but often corrected on the fly. Hamming code is often used for memory error checking.
Here is a web site which explains Hamming code better than I possibly could (this may be on the test). Here is a cached version
Thus, with RAID level 2, if there are four data disks, there would need to be three additional parity disks for a total of seven. This is not widely used, because most disk drives now include error correcting code.
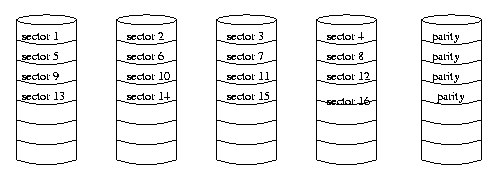
RAID level 4
The remaining levels of RAID use striping and parity, but the strips are relatively large. With RAID level 4, bit-by-bit parity is calculated across corresponding strips on each data drive, and the parity bits are stored on the corresponding strip on the parity drive.
This level incurs a performance penalty with small write operations because each write operation has to write not only the data, but also the corresponding parity bits, and this means that it has to read the old parity bit and recalculate it. Consider a system with four data disks and a parity disk. In order to write a single byte which happens to be on disk 1, the system first has to read the old data on disk 1 and the corresponding parity byte on disk 5. It then recalculates the value of the parity bits, and rewrites both the data and the parity byte. Thus one logical write operation involves two read operations and two write operations. This only makes sense on systems where most of the write operations involve writing large amounts of data. Even then, since every write has to involve the parity disk, this can be a bottleneck.
Here is a diagram for RAID level 4.
RAID level 5
RAID level 5 is similar to RAID level 4 except that the parity bits are distributed across all of the disks instead of being concentrated on one disk. This overcomes the problem of the bottleneck associated with the fact that every write operation involves the parity disk.
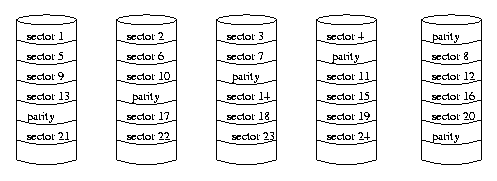
This is a very widely used system. It is very efficient for operations involving large files. For example, suppose that a process has to read a file involving 20 sectors. Rather than reading each sector sequentially, it can read the sectors four at a time in parallel (if there are four data disks), thus achieving a 400 percent speedup. When it later writes the file, it can write four sectors plus the parity sector at the same time, so again there is a 400 percent speed up compared to a single disk (minus the relatively small overhead of calculating the parity bits). Unlike levels 2 and 3, it does not involve synchronizing the drives, which is difficult to achieve.
It also has redundancy built in so that if any one disk fails completely, all of its contents can be reconstructed automatically with no loss of data. Of course if two disks fail simultaneously, all of the data is lost.
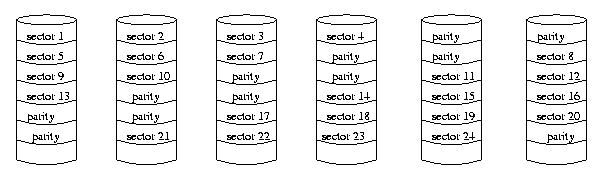
RAID level 6
RAID level 6 was introduced later. It is for systems which require very high levels of redundancy and availability. It requires the computation of two different parity calculations for each each stripe, and thus it requires two additional disks. A system which requires four data disks would have six disks in all. The advantage of RAID level 6 is that if two disks fail, no data is lost. The disadvantage is that there is a more substantial penalty incurred for small write operations since every write operation also requires calculating and writing two separate parity values.
Essentially all modern operating systems use a Graphical User Interface, or GUI. A GUI has a bit mapped monitor, in which each pixel of the monitor can be accessed by the operating system. This is in contrast to a character oriented monitor, which was the norm during the 1980s. Character oriented monitors could only display characters in fixed positions on the screen. These are of course much easier to program.
GUI interfaces typically have four features
In general, each window is the front end of a process which is running or runnable. Typically, at any given time, one window has the focus, which means that when a keystroke is entered, the value is passed to the underlying process of that window.
The classical GUI interface was developed at Xerox PARC. The first commercial implementation was on the Apple Macintosh in 1984. This was an overwhelming commercial success and received a huge amount of favorable press because up until its release, almost all computing had been text based.

At the same time, Project Athena was launched at MIT (it actually started in 1983). Predominantly funded by IBM and DEC, it developed the prototype for the modern distributed computer network. One of the products of Project Athena was X Windows, which was a GUI for Unix workstations. Today, essentially all Unix workstations, regardless of the Operating system, run X Windows. It is now generally referred to as simply X, or X11 to refer to the current version, which is 11.
Microsoft was a latecomer to the GUI world. Their command driven DOS operating system was so dominant in the PC world that they did not feel that they needed to develop GUI capabilities. Microsoft's first two attempts at a GUI interface Windows 1.0 and Windows 2.0 were commercial failures (I bet you've never heard of them). Windows 3.1 released in 1991 was their first successful GUI product, although it was nothing more than a graphical front end for DOS. Windows 95, released in 1995, was a complete reworking of the operating system and was wildly successful.
GUIs, including X, Windows 95 and its successors are event driven. Event driven programming is somewhat different from the kinds of programs that you have written so far in all of your courses. The logic is very simple, although the implementation is often messy. An event driven program displays one or more windows, tells the operating system what kinds of events it will respond to, and then has code to handle each of the possible events. Here are some examples of events.
Mouse moves
Mouse button clicks
Pressing a key
Releasing a key
Exposing a window
Typically the main portion of the program simply enters an infinite loop which senses events and for each one, it calls the appropriate function. Here is some simple pseudocode for an event driven program.
main()
{
DisplayWindow();
SetUpEventMask(); /* tell the os what events the program
will respond to */
while (true) {
GetNextEvent();
ProcessEvent();
}
}
MouseMoveEventHandler() { ... }
KeyDownEventHandler() { ... }
etc.
It is important to remember that events are asynchronous; they can occur in any order, and in general, they are processed in the order that they are received.
A GUI system always has an extensive array of graphics calls, which allow the user to draw lines, text etc. in a window. Graphics on a GUI system is fairly complicated because in general, the programmer cannot make any assumptions about the size of the window. Usually the user can change the size of a window as well as the aspect ratio (the ratio of width to height), and it is up to the programmer to make sure that whatever is being displayed in the window looks reasonable no matter what the dimensions of the window.
Although there are some conceptual similarities between these two windowing systems in that they both use very similar concepts of event driven programming, there are also some major design differences.
One major difference between X and Microsoft Windows programming is the all of the X code runs in user space, completely independent of the operating system, while Microsoft Windows code is an integral part of the operating system. There are thousands of Win32 APIs, and less than 200 Unix system calls, and the reason for this is that all of the GUI calls are APIs in Windows, but not in Unix.
Another major difference between X and Microsoft Windows is that X is designed for a distributed system while Microsoft is not. With X, the window for an application can be running on a different computer than the process itself. To use terms that you will become more familiar with later, there is an X server on a particular machine, which displays windows; and clients, which are processes which may be running on different machines, which establish a connection to a particular X server.
X Windows is much more flexible than the Windows GUI. X allows a user to choose among various window manager programs. A window manager is a program which runs on the X server and is responsible for displaying the windows. There are a number of different window managers, each of which has a slightly different look and feel.
Here is a link to a web site which discusses the concept of a window manager and has links to many of the common ones. Read the introduction. It's short.
Students often ask me why we still use text based I/O in our lower division courses. The answer is the even the simplest hello world program in Windows or X is extremely complex. Although this course will not ask you to actually write a GUI program for either X or Window NT, we will discuss how this programming works and show some short samples.
Programming X Windows
It is possible to write an X Windows program at a number of different levels.
Although the XtToolkit is written in C, it is object oriented. Widgets are classes; the implementation details are generally hidden from the user, and they often define fairly complex behaviors. There is even a class hierarchy in which widgets can inherit features from more elementary classes.
Responses to events are called callbacks. It is possible to write a program using the the XtToolkit with no callbacks. It would display one or more windows, but it wouldn't do anything else. The programmer is responsible for writing callback routines which specify what the program should do in response to specific events.
Here is a short example of an X Windows program. It displays a window with two pushbuttons, labeled Hello and Quit. When the user pushes the Hello button, a popup window appears with the default appearance for a popup window (three buttons, labeled OK, Cancel, and Help). When the user presses the Quit button, the program terminates.
/* an X demo program.
It creates a toplevel widget and four additional widgets.
A RowColumn widget holds the two buttons.
There are two PushButton widgets, "Hello" and "Quit".
Pushing the hello button causes the fourth widget, a
PopupDialog to appear.
Pushing the Quit button terminates the program.
On Solaris, compile like this gcc prog1.c -lXm -lXt
*/
#include <Xm/PushB.h>
#include <Xm/RowColumn.h>
#include <Xm/MessageB.h>
void message_callback(), quit_callback();
int main(int argc, char *argv[])
{
Widget toplevel, manager, hello_button, quit_button;
XtAppContext app;
toplevel = XtVaAppInitialize(&app,"Demo1",NULL,0,
&argc, argv, NULL, NULL);
manager = XtVaCreateWidget("manager", xmRowColumnWidgetClass,
toplevel,NULL);
hello_button = XtVaCreateWidget("Hello",
xmPushButtonWidgetClass, manager,NULL);
XtAddCallback(hello_button, XmNactivateCallback, message_callback,
NULL);
quit_button = XtVaCreateWidget("Quit",
xmPushButtonWidgetClass, manager,NULL);
XtAddCallback(quit_button, XmNactivateCallback, quit_callback, NULL);
XtManageChild(hello_button);
XtManageChild(quit_button);
XtManageChild(manager);
XtRealizeWidget(toplevel);
XtAppMainLoop(app);
return 0; /* we never get here */
}
void message_callback(Widget w, XtPointer client_data, XtPointer call_data)
{
Widget message_box;
Arg args[3];
XmString xmsg;
char *msg = "You have pushed the Hello Button";
xmsg = XmStringCreateLocalized(msg);
XtSetArg(args[0],XmNmessageString,xmsg);
message_box = XmCreateInformationDialog(w, "info", args, 1);
XmStringFree(xmsg);
XtManageChild(message_box);
XtPopup(XtParent(message_box), XtGrabNone);
}
void quit_callback(Widget w, XtPointer client_data, XtPointer call_data)
{
exit(0);
}
The function XtAppMainLoop() is the library function which contains an infinite loop to respond to events. Each widget class has predefined the events to which it will respond. The function XtAddCallback adds a callback routine to a particular widget.
Windows GUI Programming
The Microsoft approach to software development is to tightly couple the programming with the operating system (Windows 95, Windows NT or whatever). The advantage of this approach is that the user can quickly develop fairly powerful applications which do very sophisticated things without much programming, but the disadvantage is that all portability is lost. Also, the learning curve to write even trivial applications is fairly steep.
Windows programming can be done at two levels: programming in C with the Windows Application Program Interface (API), and programming with the Microsoft Foundation Classes (MFC). The latter is a set of classes which build on the Windows API.
Code using either of these methods does not look much like the code that you have developed so far. For example, there is no concept of a controlling terminal, so you can't use the I/O library functions like printf, scanf (or cin and cout in C++). There is not even a function called main() (at least not in any code that the programmer writes; main is hidden in one of the API calls). The entry point for a windows program is a function named WinMain; this function creates a window and then enters an infinite loop. This loop receives events (called messages in Windows terminology) and acts on them. Events include such things as moving the mouse, hitting a key, depressing a mouse button, releasing a mouse button, or messages from the operating system to resize the window. The actions which are called in response to events are called callbacks. There are about 200 message types; here is a list of the ten most commonly used.
| WM_CHAR | A character is input from the keyboard |
| WM_COMMAND | The user selects an item from a menu |
| WM_CREATE | A window is created |
| WM_DESTROY | A window is destroyed |
| WM_LBUTTONDOWN | The left mouse button is pressed |
| WM_LBUTTONUP | The left mouse button is released |
| WM_MOUSEMOVE | The mouse pointer is moved within the window |
| WM_PAINT | The window needs repainting (because it was resized |
| or because part of it had been covered by another | |
| window and has become exposed | |
| WM_QUIT | The application is about to terminate |
| WM_SIZE | A window is resized |
The user writes callback code which is invoked by each of the various messages, and this is the essence of windows programming. As events occur, they are put in a queue, and the main loop of the the program retrieves these messages and acts on them according to these functions.
The Microsoft Foundation Classes (MFC)
The Microsoft Foundation Classes are a set of some 200 classes which place an object-oriented wrapper around the Windows APIs. Consistent with the OO philosophy, everything is a class. For example, there is an application class CWinApp and your application is a class derived from this. There are several window classes, such as CFrameWnd, and your windows are classes derived from these. MFC makes heavy use of inheritance, and all classes fit into a class hierarchy. The root of this hierarchy is the class CObject.
Here is a simple (Ha!) program which uses MFCs. Notice that there is no obvious entry point (i.e., no function called main or WinMain) and no obvious flow of control.
// When the user depresses the left mouse button, the
// program draws the coordinates of the pointer location
// on the screen.
// Unfortunately, the window is cleared whenever it
// is resized, covered, or minimized
#include <afxwin.h>
class CMyApp : public CWinApp
{
public:
virtual BOOL InitInstance();
};
class CMyWindow : public CFrameWnd
{
public:
CMyWindow();
protected:
afx_msg void OnLButtonDown(int flags, CPoint point);
DECLARE_MESSAGE_MAP();
};
CMyApp myApp;
BOOL CMyApp::InitInstance()
{
m_pMainWnd = new CMyWindow;
m_pMainWnd->ShowWindow(m_nCmdShow);
m_pMainWnd->UpdateWindow();
return TRUE;
}
BEGIN_MESSAGE_MAP (CMyWindow, CFrameWnd)
ON_WM_LBUTTONDOWN()
END_MESSAGE_MAP()
CMyWindow::CMyWindow()
{
Create(NULL, "My First Window Application");
}
void CMyWindow::OnLButtonDown(int flags, CPoint point)
{
CClientDC dc(this);
char s[32];
sprintf(s,"[%d %d]",point.x, point.y);
dc.TextOut(point.x, point.y, s);
}
I/O in Windows and Unix
Windows
A key component device management in Windows systems is the Plug and Play manager. Plug and Play (PnP) is a combination of hardware and software support that enables the operating system to recognize and adapt to hardware configuration changes with little or no intervention by a human. New devices can be added (or devices removed) without the awkward configuration changes required by earlier systems. For example, a user can dock a portable computer and use the docking station keyboard, mouse and monitor without making manual configuration changes.
We can contrast this with earlier PC operating systems in which the process of adding a new device was a little tricky. After installing the device driver, it was usually necessary to reboot the system, and sometimes set some dip switches. Occasionally two different devices would attempt to use the same interrupt request line, with disastrous results.
With PnP, when a change in devices occurs, the operating system will automatically determine the resources needed by the device (i.e. I/O Ports, IRQs (Interrupt Request Lines), DMA channel, and memory allocation) and make the appropriate assignments. It can even dynamically load the appropriate device driver. If two devices request the same IRQ, The PnP manager will automatically resolve the conflict.
This leads to another feature of modern device management. The old model of a computer with a single bus has been replaced by a much more complex, multiple bus system. Compare Figure 1.5 on page 21 of your text with Figure 1.11 on page 32 of your text. An operating system with PnP will build a device tree at boot time, and update this as needed. Here is an example (copied from the Microsoft Device Driver Development Kit Help pages).
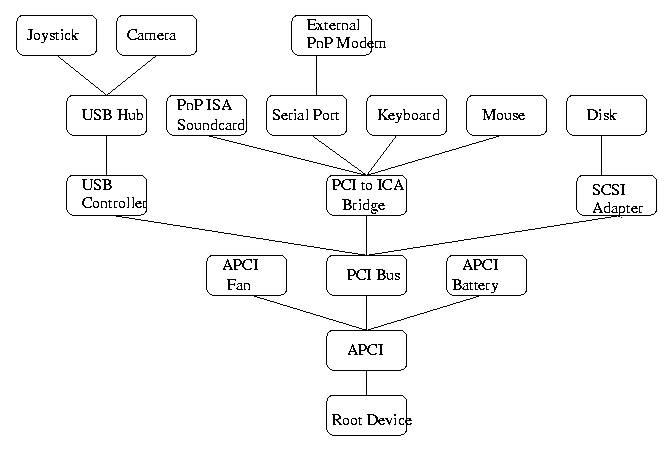
For example, many systems now have a SCSI (Small Computer System Interface) Adapter. This is technically a bus rather than just an adapter, since several different peripheral devices can be attached to this at the same time. The transmission rate is faster than the standard serial or parallel ports.
SCSI has been around for a while. A newer I/O external bus standard is the Universal Serial Bus (USB). Like the SCSI, this allows numerous (up to 127) peripherals to be connected through one port.
I/O in Unix
In most Unix systems, devices are made to look like files. They are
opened with the same system calls and read and written with the same
system calls. All of the information about devices is in a directory
named /dev. Here are some of the files in a typical
linux directory along with a description.
| /dev/fd0 | Floppy disk |
| /dev/hda | First IDE disk |
| /dev/hda2 | Second partition of first IDE disk |
| /dev/hdb | Second IDE disk |
| /dev/ttyp0 | Terminal |
| /dev/console | Console |
| /dev/lp1 | Parallel printer |
The following snippet of code opens the floppy drive on my linux box and reads the first sector (sectors are 512 bytes). Subsequent calls to read would read subsequent sectors.
fd = open("/dev/fd0",O_RDONLY);
n = read(fd,buffer,512);
Linux allows users to install a device driver on the fly, without rebooting the system.